compression
TurboQuant: Google’s Breakthrough in Efficient Large Language Model KV Cache Management Promises Unprecedented Compression Without Accuracy Loss
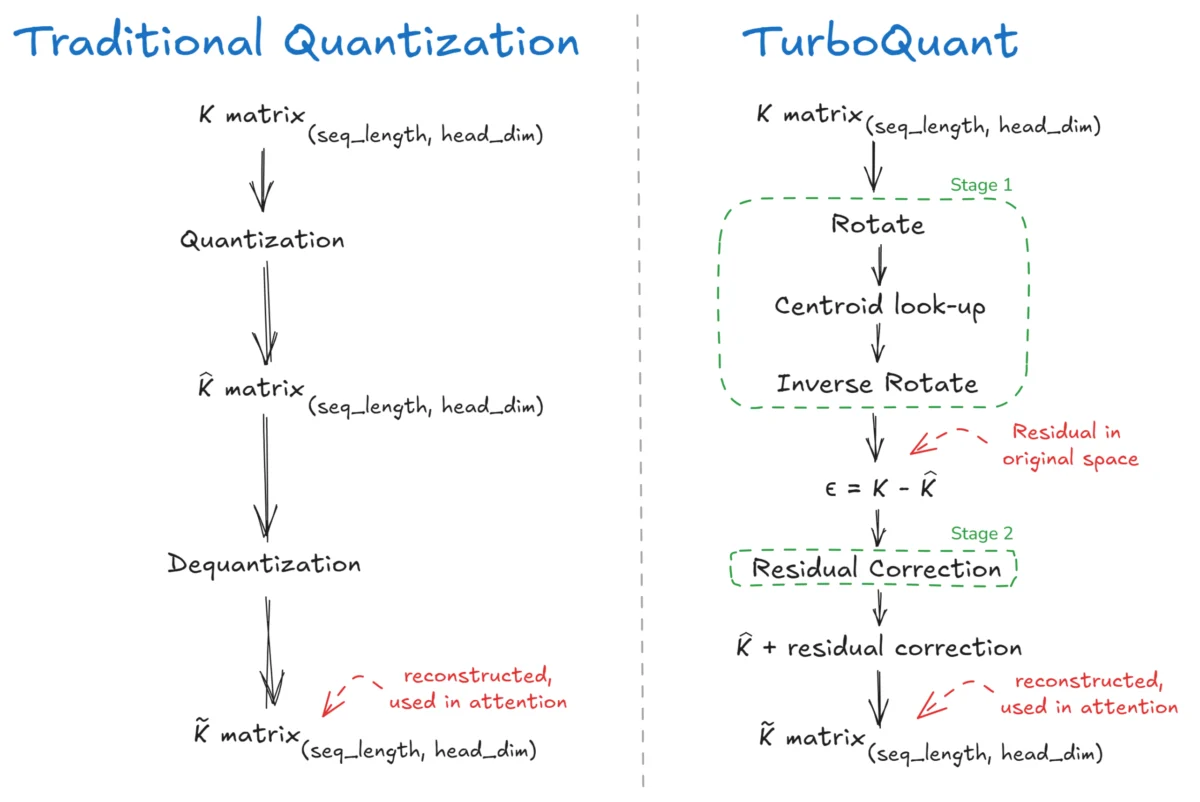
The intricate workings of Large Language Models (LLMs) have long been attributed to a core mechanism known as "attention," the conceptual brain that allows these powerful AI systems to discern relationships between different parts of the input data. This attention mechanism, operating on Query (Q), Key (K), and Value (V) components, is fundamental to the […]