accuracy
TurboQuant: Google’s Breakthrough in Efficient Large Language Model KV Cache Management Promises Unprecedented Compression Without Accuracy Loss
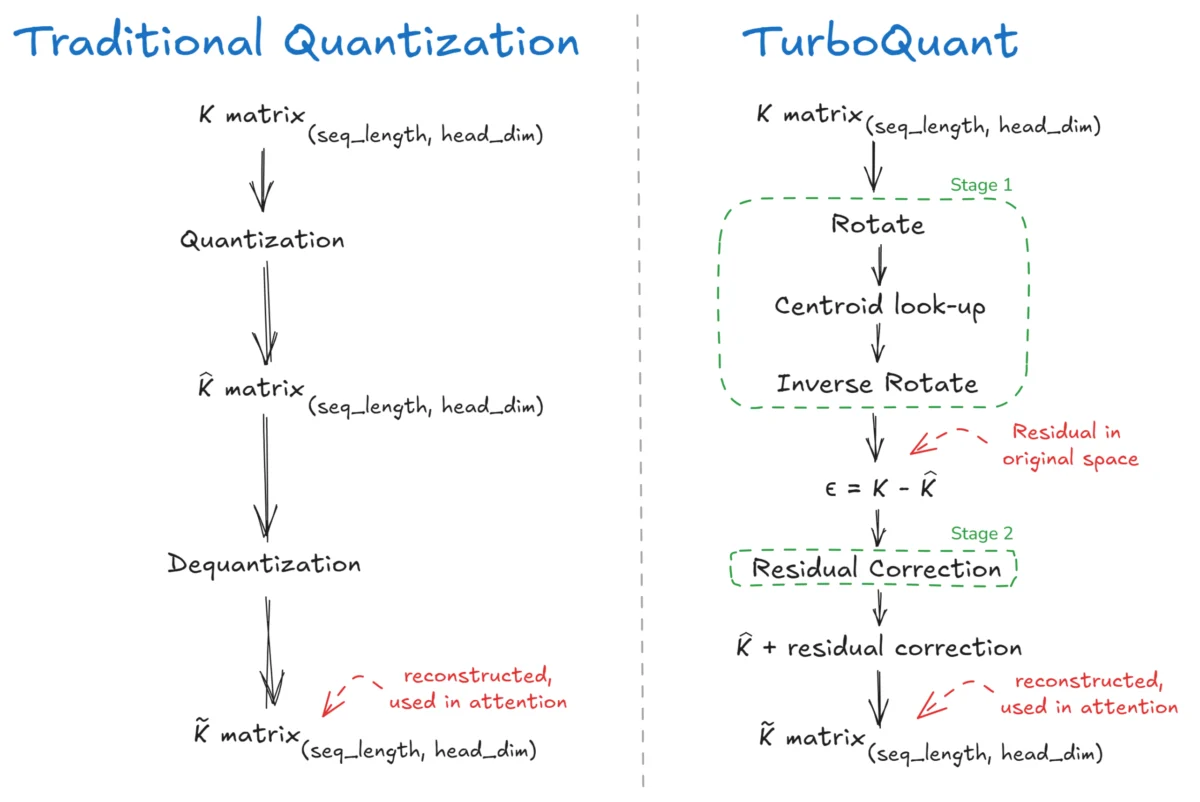
The intricate workings of Large Language Models (LLMs) have long been attributed to a core mechanism known as "attention," the conceptual brain that allows these powerful AI systems to discern relationships between different parts of the input data. This attention mechanism, operating on Query (Q), Key (K), and Value (V) components, is fundamental to the […]

Proxy-Pointer RAG Achieves Vectorless Accuracy at Vector RAG Scale and Cost
In a significant advancement for Retrieval Augmented Generation (RAG) systems, a novel architecture named Proxy-Pointer RAG has demonstrated unprecedented accuracy and efficiency, particularly when processing complex, structured documents. This development addresses a long-standing challenge in the field: bridging the gap between the precision of "vectorless" RAG approaches and the scalability required for enterprise-level applications. The […]