
The Crucial Role of Memory Architecture in Autonomous LLM Agents: A Deep Dive into Mechanisms, Evaluation, and Emerging Frontiers
The landscape of autonomous large language model (LLM) agents is rapidly evolving, with a growing consensus that the true differentiator lies not in the underlying model, but in the sophistication of their memory architecture. This realization comes as practitioners grapple with the complexities of coordinating distributed multi-agent systems, a challenge highlighted by ongoing development in platforms like OpenClaw and AWS AgentCore. Nicholaus Lawson, a Solution Architect with extensive experience in software engineering and AI/ML, recently shared insights into this critical domain, drawing parallels between his iterative, hands-on experience and the formal taxonomy presented in the research paper "Memory for Autonomous LLM Agents: Mechanisms, Evaluation, and Emerging Frontiers" (arxiv 2603.07670).
Lawson’s personal journey with multi-agent systems, particularly within his OpenClaw setup, involves a complex interplay of specialized agents such as research, writing, and simulation engines, all orchestrated by a heartbeat scheduler. These agents collaborate asynchronously, exchange context through shared files, and crucially, maintain state across sessions that can span days or even weeks. However, integrating these bespoke systems with third-party agentic frameworks like Claude Code or agents deployed on AWS AgentCore introduces significant hurdles in coordination, memory management, and state persistence. It is within this practical struggle that Lawson identified a fundamental truth: the efficacy of these agents hinges predominantly on their memory architecture, not the selection of the LLM itself.
The aforementioned research paper, which Lawson encountered, offered a formal framework that closely mirrored his own empirical discoveries. The paper’s taxonomy not only validated his findings but also illuminated the broader industry challenges and the shared pain points faced by developers in this burgeoning field. This article delves into the paper’s core findings and Lawson’s real-world experiences, offering a comprehensive look at why memory is paramount for autonomous agents.
Why Memory Matters More Than You Think: Recalibrating Priorities
The research paper begins with a stark empirical observation that serves as a foundational principle for anyone building or evaluating LLM agents: "The gap between ‘has memory’ and ‘does not have memory’ is often larger than the gap between different LLM backbones." This assertion has profound implications for development priorities. While significant energy is often expended on model selection and intricate prompt tuning, memory is frequently relegated to an afterthought. The paper argues this approach is fundamentally backward.
To formalize the concept, the paper frames agent memory within the context of a Partially Observable Markov Decision Process (POMDP). In this framework, memory functions as the agent’s "belief state" within a world that is not fully transparent. An agent, by definition, cannot perceive every aspect of its environment. Consequently, it constructs and maintains an internal model of reality – this model is its memory. Any inaccuracies or omissions in this internal model inevitably degrade every subsequent decision made by the agent. This underscores the critical need for robust and accurate memory systems.
The Write-Manage-Read Loop: Beyond Simple Storage
The paper characterizes agent memory not merely as a "store and retrieve" function, but as a dynamic "write-manage-read loop." This loop highlights three distinct yet interconnected phases:
- Write: The process of capturing new information and experiences.
- Manage: The critical step of curating, organizing, prioritizing, and potentially summarizing or discarding information.
- Read: The retrieval and utilization of relevant information for decision-making.
Lawson observes that many current implementations excel at the "write" and "read" phases but largely neglect the "manage" aspect. This leads to an accumulation of data without proper curation, resulting in an influx of noise, contradictory information, and bloated context windows that hinder agent performance. The "manage" phase, often overlooked, is precisely where most systems encounter their most significant challenges.
Before recent enhancements to his OpenClaw system, Lawson relied on heuristic control policies to manage memory. These involved explicit rules for what data to store, when to summarize, when to escalate to long-term storage, and when to allow information to age out. While not an elegant solution, this approach forced a deliberate engagement with the management step. In other systems, he leverages mechanisms like AgentCore’s short-term and long-term memory capabilities, as well as vector databases. However, he notes that file-based memory systems, while viable for individual agents or chatbots, do not scale effectively for large, distributed architectures.
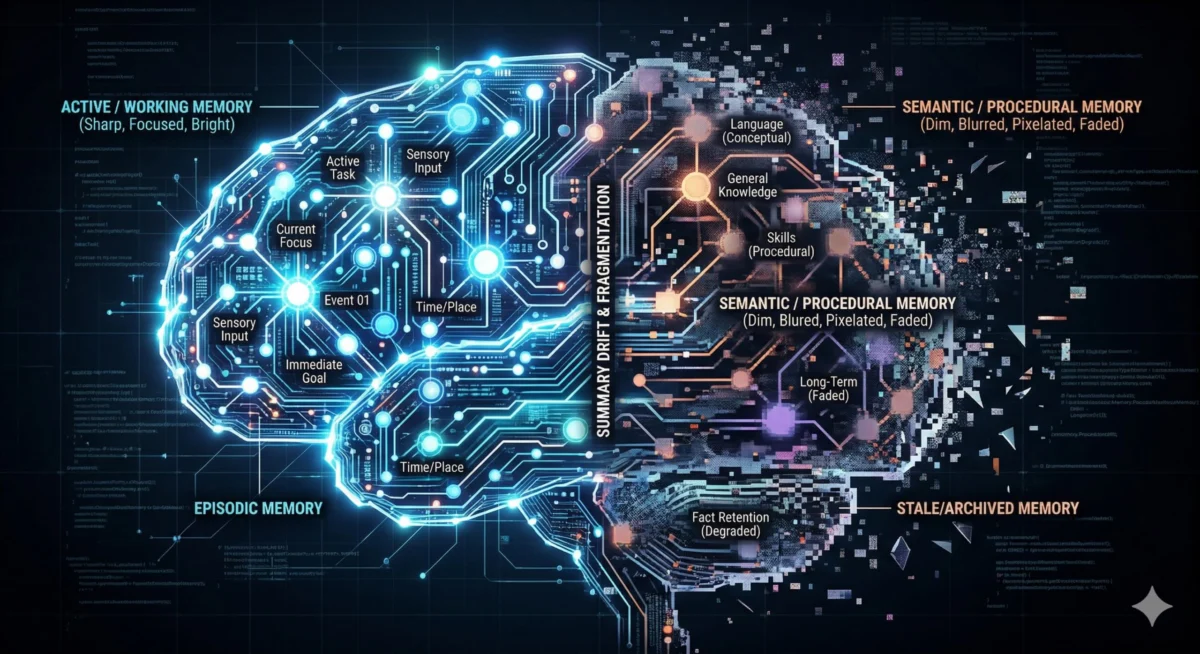
Four Temporal Scopes of Memory: A Practical Taxonomy
The research paper delineates memory into four distinct temporal scopes, providing a valuable framework for understanding how agents interact with information over time. Lawson maps these scopes to his practical experiences:
Working Memory: The Ephemeral Context Window
Working memory represents the agent’s immediate context window. It is characterized by its ephemeral nature, high bandwidth, and inherent limitations. Information resides here only briefly. A primary failure mode is "attentional dilution," where relevant information is overlooked due to an overcrowded context window, leading to the well-known "lost in the middle" effect. Lawson and many development teams have encountered this issue. When the context in systems like OpenClaw, Claude Code, or chatbots becomes excessively long, agent behavior degrades in ways that are difficult to diagnose. The model technically "possesses" the information but fails to utilize it effectively. A common workaround observed among teams, including Lawson’s own, is the creation of new threads for distinct tasks, avoiding prolonged, high-task-volume sessions that degrade performance over time.
Episodic Memory: Chronicling Experiences
Episodic memory captures concrete experiences, detailing what happened, when, and in what sequence. Within Lawson’s OpenClaw setup, this is exemplified by daily stand-up logs. Each agent contributes a concise summary of its activities, findings, and any escalated issues. These entries accumulate into a searchable timeline, offering immense practical value. Agents can review past work, identify recurring patterns, and avoid repeating previous mistakes. Tools like Claude Code often require explicit instructions to replicate this behavior. In production environments, mechanisms within platforms like AgentCore’s short-term memory can store these episodic records, and intelligent systems can discern which memories warrant persistence beyond a single interaction. The research paper validates episodic memory as a distinct and crucial tier of agent memory.
Semantic Memory: Distilled Knowledge and Heuristics
Semantic memory is responsible for storing abstracted, distilled knowledge, facts, heuristics, and learned conclusions. In Lawson’s OpenClaw system, this is embodied in the MEMORY.md file within each agent’s workspace. This memory is curated; not all information is preserved. The agent, or Lawson periodically, determines what constitutes enduring truth versus situational context. On AgentCore, this function is primarily fulfilled by the Long-term memory feature. The curation step is paramount; without it, semantic memory devolves into a disorganized repository.
Procedural Memory: Encoding Skills and Behaviors
Procedural memory encompasses encoded executable skills, behavioral patterns, and learned behaviors. In OpenClaw, this maps to files like AGENTS.md and SOUL.md, which contain persona instructions, behavioral constraints, and escalation protocols. When an agent loads these at the beginning of a session, it is essentially loading its procedural memory. Lawson acknowledges that this is an area where he and many development teams have been remiss, dedicating significant time to prompt tuning but neglecting the feedback mechanisms that drive the storage and iteration of procedural memory. The research paper’s formalization of procedural memory as a distinct tier is validating, emphasizing that these are not mere system prompts but long-term learned behaviors that shape every agent action.
Five Mechanism Families: Architectures for Memory
The research paper further categorizes memory mechanisms into five families, offering insights into the architectural approaches employed by LLM agents:
Context-Resident Compression
This family includes strategies like sliding windows, rolling summaries, and hierarchical compression – all aimed at keeping information within the active context window. Rolling summaries, while appearing efficient, can lead to a loss of detail over time. Lawson notes that users often encounter systems like Claude Code or Kiro CLI compressing conversations when they exceed context limits, suggesting that restarting new threads might sometimes be a more effective strategy.
Retrieval-Augmented Stores (RAG)
Applied to agent interaction history rather than static documents, RAG involves embedding past observations and retrieving relevant memories based on similarity. This is potent for long-running agents with extensive histories. However, the quality of retrieval becomes a critical bottleneck. Inaccurate embeddings can lead to missed relevant memories and the surfacing of outdated information. Furthermore, queries like "what happened last Monday?" may not yield high-quality results.
Reflective Self-Improvement
Systems such as Reflexion and ExpeL fall into this category, where agents generate verbal post-mortems and store conclusions to inform future operations. The concept of agents learning from mistakes and improving is compelling. However, failure modes within this approach can be severe. Lawson posits that "dream"-based reflection and patterns like the Google Memory Agent also belong to this class.
Hierarchical Virtual Context
Inspired by MemGPT’s operating system-like architecture, this approach uses a main context window as "RAM," a recall database as "disk," and archival storage as "cold storage," with the agent managing its own paging. While conceptually interesting, Lawson observes that the overhead and complexity of maintaining these distinct tiers can be burdensome and prone to failure. He notes that despite the existence of the MemGPT paper and its GitHub repository for nearly three years, widespread production use remains elusive.
Policy-Learned Management
This represents a cutting-edge frontier where Reinforcement Learning (RL) trained operators manage memory operations (store, retrieve, update, summarize, discard). Lawson sees significant promise in this area but notes the lack of readily available tools for builders and the absence of documented production deployments.
Understanding Memory Failure Modes
The paper also meticulously outlines critical failure modes that can compromise the integrity and effectiveness of agent memory systems:
Context-Resident Failures
- Summarization Drift: Repeatedly compressing history to fit context windows leads to the loss of details, resulting in memories that no longer accurately reflect past events. This is a common issue observed in prolonged coding sessions without thread separation. Linking raw memories to consolidated ones is a proposed mitigation strategy.
- Attention Dilution: Even with massive context windows, agents can struggle to focus on pertinent information within a crowded prompt. This "attention dilution" means relevant memories, though present, are not effectively utilized.
Retrieval Failures
- Semantic vs. Causal Mismatch: Similarity searches can return information that appears related but is not causally linked. Embeddings excel at identifying textual resemblance but struggle with understanding causality. This often manifests in debugging scenarios where similar errors are identified, but the root cause is missed, leading to unproductive cycles of changes.
- Memory Blindness: In tiered memory systems, crucial facts may never be retrieved due to limitations in retrieval mechanisms, such as sliding windows or the retrieval of a fixed number of top results.
- Silent Orchestration Failures: Paging, eviction, or archival policies may malfunction without generating explicit errors, leading to a gradual degradation of response quality and grounding. Lawson experienced this when OpenClaw failed to write daily memory files, causing a loss of crucial daily summaries and an inability to recall past work.
Knowledge-Integrity Failures
- Staleness: External information changes, but the agent’s memory does not, leading to decisions based on outdated facts. This is commonly observed with LLMs providing incorrect dates, referencing past political figures, or being unaware of recent technological advancements.
- Self-Reinforcing Errors (Confirmation Loops): When an agent treats an inaccurate memory as ground truth, its perception of reality becomes skewed. Lawson’s OpenClaw system, for instance, incorrectly deemed a SmartThings integration faulty due to dead batteries, leading it to disregard all subsequent data from that device.
- Over-Generalization: Lessons learned in narrow contexts are applied universally, turning specific workarounds into default patterns.
Environmental Failure
- Contradiction Handling: Conflicting information can create significant challenges. Lawson’s OpenClaw system oscillated between believing N8N workflows were successfully created and believing they had failed, even after verification, due to a timeout error masking the actual success.
Navigating Design Tensions in Memory Systems
The development of robust memory systems for autonomous agents involves navigating several inherent design tensions:
- Utility vs. Efficiency: Enhancing memory capabilities often leads to increased token usage, latency, storage requirements, and system complexity.
- Utility vs. Adaptivity: Memory that is highly useful at one point may become stale over time, and the process of updating it can be costly and risky.
- Adaptivity vs. Faithfulness: Frequent revisions, updates, and compressions increase the risk of distorting the original historical record.
- Faithfulness vs. Governance: Accurate memory might contain sensitive information (PHI, PII) requiring deletion, obfuscation, or protection, creating a conflict with the need for faithful record-keeping.
- All of the Above vs. Governance: Enterprise-level compliance requirements can impose significant constraints on memory system design and implementation.
Practical Takeaways for LLM Agent Builders
For engineering teams seeking guidance on memory systems, Lawson offers several practical takeaways:
- Start with Explicit Temporal Scopes: Rather than building a monolithic "memory" system, focus on developing specific memory types (episodic, semantic, etc.) as use cases emerge. Avoid premature over-engineering.
- Prioritize the Management Step: Plan for memory maintenance. Establish strategies for compression, summarization, and information curation. Clearly define how data will transition between different memory types (e.g., RAG vs. semantic). Neglecting this step leads to noise and system degradation.
- Retain Raw Episodic Records: Do not rely solely on summaries, as they can lose critical details. Raw records provide a verifiable source of truth and allow for the retrieval of specific information when needed.
- Version Reflective Memory: Incorporate timestamps or versioning for summaries, long-term memories, and compressed data to help agents discern the most accurate and current information, mitigating contradictions.
- Treat Procedural Memory as Code: Consider files like
AGENTS.mdandMEMORY.mdas integral parts of the memory architecture. Version control these files to track changes, especially if autonomous systems can modify them based on feedback.
Conclusion: Memory as the True Differentiator
The "write-manage-read" framing introduced by the research paper is a powerful and complete paradigm that compels developers to consider all three phases of memory interaction, moving beyond a simplistic "store and retrieve" mentality. The paper’s taxonomy not only validates Lawson’s iterative discoveries but also formalizes patterns that practitioners have independently identified, offering a shared vocabulary and a robust framework for clear thinking.
The paper candidly addresses the remaining open challenges, including the primitive state of memory evaluation, the often-overlooked aspect of governance, and the nascent promise of policy-learned management. These represent significant opportunities for future innovation. Ultimately, the research underscores a crucial point: the true differentiation in autonomous agent systems lies not in the LLM model or the prompts, but in the sophisticated architecture of their memory. This paper provides the essential tools to understand and build more effective and reliable agent systems.
Nicholaus Lawson is a Solution Architect with a background in software engineering and AIML. He has worked across many verticals, including Industrial Automation, Health Care, Financial Services, and Software companies, from start-ups to large enterprises. This article and any opinions expressed by Nicholaus are his own and not a reflection of his current, past, or future employers or any of his colleagues or affiliates. Feel free to connect with Nicholaus via LinkedIn at https://www.linkedin.com/in/nicholaus-lawson/.


Related Posts

Unlocking Engineering Efficiency: A Deep Dive into Anthropic’s Claude Cowork for Enhanced Productivity
Uncertainty Quantification in Machine Learning: A Deep Dive into Evidential Deep Learning and Deep Evidential Regression


{kind=link}