
Unpacking the Architectural Nuances of Large Language Models: Beyond the API Prompt
The explosive growth of Large Language Models (LLMs) has fundamentally altered how we interact with artificial intelligence. While the everyday user typically engages with these sophisticated systems through polished Application Programming Interfaces (APIs) – a simple prompt eliciting a generated response – this streamlined experience often obscures the profound architectural complexities and critical design choices that underpin their capabilities. These non-obvious decisions profoundly influence an LLM’s speed, cost, and overall performance, and are paramount for developers seeking to build, fine-tune, or optimize these powerful tools.
To demystify these underlying mechanisms, a recent deep dive into the implementation of GPT-2 from scratch using only PyTorch has illuminated six pivotal architectural considerations. This hands-on approach, augmented with advanced techniques like LoRA (Low-Rank Adaptation), RoPE (Rotary Positional Embeddings), and KV Cache, has revealed crucial insights that extend beyond the user-facing API.
The Evolution of Fine-Tuning: LoRA and its Rank-Stabilized Successor
The efficiency of fine-tuning LLMs has been dramatically improved by techniques like Low-Rank Adaptation (LoRA). Traditional fine-tuning methods often require updating millions, if not billions, of parameters, making the process computationally intensive and memory-prohibitive. LoRA offers a more parsimonious approach by introducing trainable low-rank matrices, denoted as B and A, alongside the frozen pre-trained weights (W). These matrices, with dimensions (dimension x rank) and (rank x dimension) respectively, drastically reduce the number of trainable parameters. In some implementations, this reduction can be as substantial as 0.18% of the total model weights.
The core of LoRA’s adaptation mechanism is captured by the formula:
$W + Delta W = W + fracalphar(B times A)$

Here, $alpha$ (alpha) and $r$ (rank) are hyperparameters that act as a scaling factor. The ratio $alpha/r$ dictates the degree of influence the newly fine-tuned parameters have on the original weights. A higher ratio amplifies the impact of the fine-tuned components. For instance, with $alpha=32$ and $r=16$, the scaling factor is 2, effectively doubling the importance of the adapted weights. This scaling mechanism allows for fine-grained control over the adaptation process.
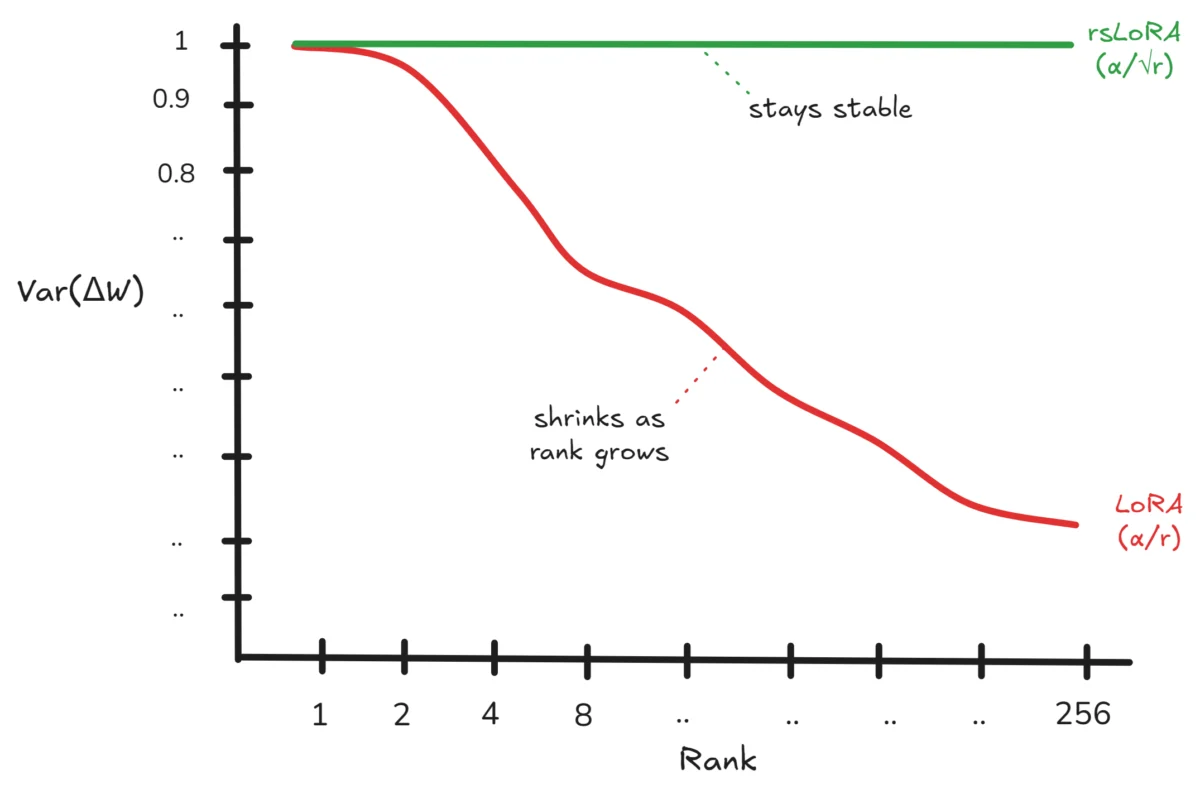
However, research has identified a subtle limitation within the standard LoRA formulation. As the rank ($r$) increases, a phenomenon occurs where the variance of the fine-tuned weights ($Delta W$) diminishes proportionally to $1/r$. This mathematical reality means that as LoRA attempts to capture more complex adaptations by increasing its rank, the magnitude of the individual weight updates paradoxically shrinks, potentially leading to reduced effectiveness without explicit user awareness.
The mathematical underpinnings of this observation stem from the initial random initialization of matrices B and A, typically drawn from a normal distribution. As the rank $r$ grows, the variance of the product $B times A$ increases linearly with $r$. When this product is scaled by $(alpha/r)^2$, the overall variance of $Delta W$ becomes proportional to $1/r$.
To counteract this effect, a modification known as Rank Stabilized LoRA (RsLoRA) has been proposed. By replacing the rank $r$ in the denominator of the scaling factor with a modified term, often denoted as $sqrtr$ or similar stabilization mechanisms, RsLoRA ensures that the variance of $Delta W$ remains constant irrespective of the chosen rank. This stabilization is crucial for maintaining consistent learning dynamics and preventing the fine-tuning process from becoming less impactful as the model complexity increases. The visual representation clearly illustrates how LoRA’s weight updates can shrink with increasing rank, while RsLoRA maintains a stable variance, ensuring more robust and consistent adaptation.
The Critical Role of Positional Embeddings: From Sinusoidal to Rotary
The way a model understands the order of words in a sentence – its positional information – is as vital as the meaning of the words themselves. Early transformer architectures, famously introduced in "Attention Is All You Need," employed Sinusoidal Positional Embeddings (PEs). This approach utilized a fixed mathematical formula to generate positional encodings, meaning it didn’t involve any trainable parameters. While this offered computational efficiency, it had significant drawbacks. The fixed nature of sinusoidal PEs limited their ability to flexibly capture relative positional relationships, primarily encoding absolute positions. Furthermore, directly adding these embeddings to token embeddings could alter the inherent magnitude of the token’s semantic information, potentially diluting its meaning.
Subsequent models, including GPT-2 and GPT-3, transitioned to a Learned Parameters approach. Here, the model learns positional information through backpropagation, allowing for greater flexibility. However, this method introduced additional parameters (context_size * dimension) and still suffered from the issue of directly adding positional information to token embeddings, potentially corrupting the original semantic signal.

Rotary Positional Embeddings (RoPE), introduced in the RoFormer architecture, represents a significant advancement. RoPE overcomes the limitations of its predecessors by encoding positional information through rotation operations applied to the Query (Q) and Key (K) matrices within the attention mechanism. Crucially, this rotation is dependent on the token’s position and frequency. This elegant solution achieves two key benefits simultaneously: it introduces no additional parameters to the model and avoids direct addition to token embeddings, thus preserving the integrity of the original token representations. This has led to RoPE becoming a de facto standard in most modern LLMs, including LLaMA and Mistral.
Weight Tying: A Scalability Dilemma
Weight tying, a technique where the weights of the token embedding layer are shared with the output projection head, was a common practice in earlier LLMs like GPT, GPT-2, and BERT. The intuition behind this was that the embedding layer maps tokens to vectors, and the output layer maps vectors back to tokens, making them natural transposes of each other. For models with around 124 million parameters, this could lead to substantial parameter savings, often around 30%, which was a significant advantage at the time.
However, as LLMs scaled to billions of parameters, the relative savings from weight tying became negligible, often less than 0.5% of the total model parameters. Consequently, most contemporary large-scale models, such as LLaMA, Mistral, and Falcon, have opted for separate embedding and output projection layers. This separation grants the output head greater freedom to specialize its mappings independently. While weight tying remains a viable and beneficial technique for smaller models, its practical relevance diminishes considerably for models operating at the scale of today’s leading LLMs.
Layer Normalization: The Stability vs. Performance Trade-off
The placement of Layer Normalization (LayerNorm) within the Transformer architecture presents a critical trade-off between training stability and final model performance. The original Transformer paper utilized "Post-LN," where normalization occurs after the residual connection. While Post-LN can sometimes lead to superior performance metrics, it is notoriously difficult to train, often plagued by exploding or vanishing gradients in deep networks.
To address these training instabilities, models like GPT-2 adopted "Pre-LN," where normalization is applied before the residual connection. This architectural shift significantly enhances training stability, making it easier to train very deep models. However, this stability often comes at a slight cost to the model’s ultimate representational capacity. The ongoing research in this area seeks to bridge this gap, leading to innovations like DeepNorm, RMSNorm, and Double Norm, which aim to achieve both stability and high performance. The visual comparison highlights this inherent tension, with Pre-LN favoring stability and Post-LN potentially yielding higher performance, while newer methods explore optimizing this balance.
KV Cache: Accelerating Inference at a Memory Cost
The attention mechanism, the heart of the Transformer, enables models to dynamically weigh the importance of tokens across a sequence, facilitating the capture of long-range dependencies. This mechanism comprises Query (Q), Key (K), and Value (V) components. During autoregressive inference, where tokens are generated one by one, each new token attends to all previously generated tokens. A naive implementation would involve recomputing the K and V matrices for all preceding tokens at every step, leading to a quadratic time complexity of $O(T^2)$ for a sequence of length $T$.

The introduction of the KV Cache is a pivotal optimization that dramatically accelerates inference. Instead of recomputing K and V from scratch, these matrices are cached after their initial computation. For each new token, only its K and V are computed and appended to the cache. Subsequent attention calculations then retrieve the vast majority of K and V values instantly from memory. This optimization reduces the time complexity of attention computation to $O(T)$.
While the computational speedup is substantial – potentially reducing attention compute by a factor of 15 for a 15-token sequence, translating to an approximate 2x overall speedup in practice – the KV cache introduces a significant memory overhead. The memory footprint scales with the number of layers, sequence length, and dimension of the model. For LLMs operating with very long contexts, this memory consumption can become a bottleneck, limiting the ability to process lengthy inputs or requiring extensive hardware resources.
A recent breakthrough by Google Research, detailed in their paper "TurboQuant: Online Vector Quantization with Near-Optimal Distortion Rate," addresses this memory challenge. TurboQuant introduces a method to compress the KV cache down to just 3 bits per value. This technique achieves a 5x to 6x reduction in memory consumption with no discernible loss in accuracy. It achieves this by cleverly rotating dimensional coordinates to follow a Beta distribution, followed by Lloyd-Max Quantization and a 1-bit Quantized Johnson-Lindenstrauss transform to mitigate residual errors. This innovation has the potential to significantly unburden memory constraints, enabling LLMs to handle much larger contexts and reducing the need for multiple GPUs on a single chip.
Quantization: The Calculated Omission of LayerNorm
The sheer scale of modern LLMs necessitates efficient methods for storage and computation. Quantization, the process of reducing the numerical precision of model weights (e.g., from 32-bit floating point to 8-bit integers, INT8), is a crucial technique for achieving this. Quantization significantly reduces memory requirements and accelerates inference, making it an indispensable tool for deploying LLMs in production environments.
However, quantization is not applied uniformly across all layers of a model. A notable exception is the Layer Normalization layer, which is almost universally skipped during INT8 quantization. This decision is rooted in a pragmatic cost-benefit analysis. While quantizing LayerNorm might offer a marginal reduction in memory or compute, the impact on model quality can be disproportionately negative. LayerNorm layers are highly sensitive to precision reduction, and quantizing them often leads to a noticeable degradation in performance without yielding significant practical gains. Consequently, LayerNorm layers are typically preserved in their full precision (e.g., FP16 or FP32) to maintain model accuracy.
This observation underscores a broader principle in quantization: not all parameters are equally amenable to precision reduction. The decision to quantize a specific layer hinges on a careful evaluation of the potential memory savings against the layer’s sensitivity to precision loss and its overall impact on the model’s quality.

Conclusion: The Unseen Architecture Matters
These six architectural considerations – the nuances of LoRA and its stabilization, the superiority of RoPE for positional encoding, the scalability challenge of weight tying, the stability-performance trade-off in LayerNorm placement, the efficiency and memory cost of KV caching, and the strategic quantization of LayerNorm – are not arcane secrets. They are fundamental design choices embedded within the architecture of virtually every major LLM.
While user-facing APIs abstract away these complexities, a deep understanding of these underlying mechanisms is essential for anyone aiming to build, fine-tune, or optimize LLMs. The decision to implement RsLoRA over standard LoRA, to employ RoPE for positional information, or to carefully manage KV cache memory, directly impacts the performance, cost, and scalability of these systems.
The journey of building an LLM from scratch, as undertaken in the referenced implementation, forces a confrontation with each of these decisions, stripping away abstractions and revealing the intricate engineering involved. This hands-on experience is invaluable for truly comprehending how these systems function, moving beyond mere usage to genuine understanding. As the field continues to advance, further exploration into areas like the mathematical intricacies of quantization errors and the practical challenges of large-scale LLM deployment will undoubtedly yield deeper insights into the future of artificial intelligence.


Related Posts

Unlocking Engineering Efficiency: A Deep Dive into Anthropic’s Claude Cowork for Enhanced Productivity
Uncertainty Quantification in Machine Learning: A Deep Dive into Evidential Deep Learning and Deep Evidential Regression


{kind=link}