
Uncertainty Quantification in Machine Learning: A Deep Dive into Evidential Deep Learning and Deep Evidential Regression
Decision-making, even for humans, is a complex process heavily influenced by intuition and an implicit understanding of uncertainty. This article delves into Evidential Deep Learning (EDL), a novel framework designed to quantify both epistemic and aleatoric uncertainty in machine learning models. Specifically, it focuses on Deep Evidential Regression (DER), as detailed in the seminal 2020 paper by Amini et al. The exploration aims to demystify these concepts and provide an accessible understanding of DER’s potential and current limitations, supported by practical examples and code demonstrations.
The increasing deployment of Artificial Intelligence (AI) and Deep Learning (DL) systems in high-stakes environments, from autonomous vehicle navigation to medical diagnostics, underscores the critical need for these systems to accurately represent their confidence and limitations. Traditional machine learning models, particularly classification models utilizing the softmax function, often present a false sense of certainty. The softmax function, designed to output probabilities that sum to one, can mislead by assigning a definitive class even when presented with data far outside its training distribution. This limitation becomes starkly apparent when models encounter Out-of-Distribution (OOD) data, where they lack a robust mechanism to express uncertainty, forcing them into potentially erroneous classifications.
Understanding the Nuances of Uncertainty
To address this fundamental challenge, researchers have broadly categorized uncertainty into two distinct types:
-
Aleatoric Uncertainty: This form of uncertainty is inherent to the data itself. It arises from noise in the measurements or inherent randomness in the data-generating process. For instance, in a medical image, aleatoric uncertainty might stem from the subtle variations in tissue density or the resolution of the imaging equipment. This type of uncertainty cannot be reduced by collecting more data, as it is a fundamental property of the observed phenomena.
-
Epistemic Uncertainty: In contrast, epistemic uncertainty is associated with the model’s knowledge or lack thereof. It reflects the model’s ignorance about the underlying function it is trying to learn. This uncertainty is particularly pronounced in regions of the input space where the model has not been trained or has limited data. Collecting more diverse and representative data can help reduce epistemic uncertainty, as it allows the model to refine its understanding of the underlying patterns.

The ability to disentangle and quantify these two types of uncertainty is crucial for building trustworthy AI systems. Imagine an autonomous vehicle needing to decide whether to proceed through an intersection. If the uncertainty about an oncoming pedestrian is primarily aleatoric (e.g., due to a slight visual obstruction), the vehicle might proceed cautiously. However, if the uncertainty is epistemic (e.g., the pedestrian is in an unusual location not well-represented in the training data), a more conservative action, such as braking, would be warranted.
Existing Approaches to Uncertainty Quantification (UQ)
Before the advent of Evidential Deep Learning, several prominent methods were employed for uncertainty quantification, each with its own strengths and computational demands:
-
Deep Ensembles: This approach involves training multiple independent neural networks, typically with different random initializations. During inference, the disagreement among the predictions of these individual models is used to estimate epistemic uncertainty. Aleatoric uncertainty is often estimated by averaging the predicted variances from each model for a given input. While effective, deep ensembles are computationally expensive, requiring the training and inference of numerous models.
-
Variational Inference (for Bayesian Neural Networks): Bayesian Neural Networks (BNNs) treat model weights as probability distributions rather than fixed values. Variational inference approximates these posterior distributions, allowing for the estimation of uncertainty by sampling multiple weight configurations and aggregating their predictions. This method can provide a principled approach to UQ but often comes with significant computational overhead during both training and inference.
-
Conformal Prediction: Conformal prediction is a post-hoc method that offers statistically guaranteed prediction intervals. It does not inherently disentangle epistemic and aleatoric uncertainty, instead providing a range within which a future observation is expected to fall with a certain confidence level (e.g., 95%). While providing strong theoretical guarantees, it typically requires a calibration set and can add complexity to the inference pipeline.

The primary drawback shared by these established methods is their computational cost. Training multiple models, performing numerous inference passes, or employing post-hoc calibration steps can significantly increase the time and resources required, making them less practical for real-time applications or scenarios with massive datasets.
Evidential Deep Learning: A Paradigm Shift
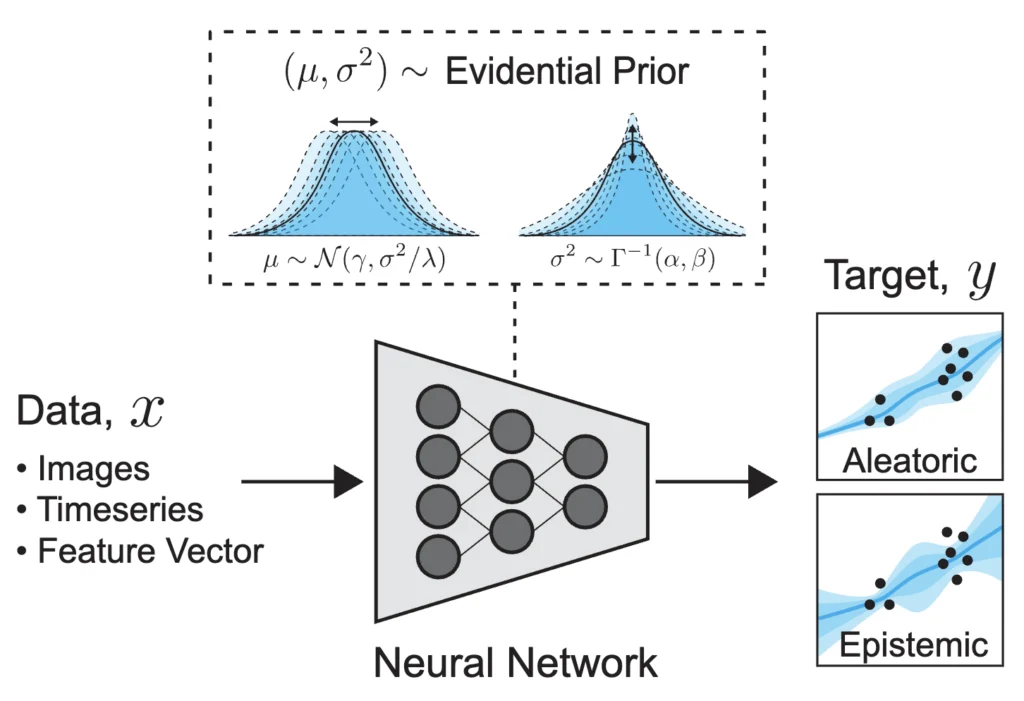
Evidential Deep Learning (EDL) emerges as a promising alternative, aiming to quantify both epistemic and aleatoric uncertainty within a single forward pass of a neural network. The core idea behind EDL is to train models to output parameters for higher-order probability distributions. Instead of directly predicting the mean and variance of a target variable, an EDL model predicts the parameters that define a distribution over these mean and variance parameters. This allows the model to express uncertainty not just about the output itself, but also about the underlying parameters governing the output distribution.
Deep Evidential Regression (DER): Theory and Application
Deep Evidential Regression (DER), a specific instantiation of EDL, focuses on regression tasks. The fundamental principle of DER is to model the unknown mean ($mu$) and variance ($sigma^2$) of a target variable not as fixed values, but as random variables themselves. To achieve this, DER models predict the parameters of a Normal Inverse Gamma (NIG) distribution for each input sample.
The NIG distribution is a bivariate distribution that describes the joint probability of a Gaussian distribution’s mean and variance. It is composed of:

- A Normal distribution for the mean ($mu$), parameterized by $gamma$ (expected mean) and $lambda$ (scale of the mean).
- An Inverse Gamma distribution for the variance ($sigma^2$), parameterized by $alpha$ (shape) and $beta$ (scale).
The relationship between these distributions can be visualized as follows: the NIG distribution provides a probabilistic framework where samples from it yield parameters for a standard Gaussian. This hierarchical structure allows the model to capture uncertainty in a more nuanced way.
The parameters of the NIG distribution, $(gamma, lambda, alpha, beta)$, are learned by the neural network. Once these parameters are obtained, DER provides specific formulas to derive aleatoric and epistemic uncertainty:
-
Aleatoric Uncertainty ($U_A$): This is calculated as $sqrtfracbetaalpha-1$. This term reflects the inherent noise and variability in the data, directly influenced by the Inverse Gamma component of the NIG distribution.
-
Epistemic Uncertainty ($U_E$): This is calculated as $sqrtfracbetalambda(alpha-1)$. This term captures the model’s uncertainty about the learned parameters. The presence of $lambda$ (which relates to the uncertainty in the mean) indicates that as the model becomes more confident about the expected mean, epistemic uncertainty decreases.
A key advantage of DER is that these uncertainty measures can be computed almost instantaneously after a single forward pass. This contrasts sharply with methods like deep ensembles, which require multiple forward passes, or variational inference, which involves sampling.
Training DER Models: The Loss Function

To train a DER model, the network is tasked with predicting the four parameters of the NIG distribution $(gamma, lambda, alpha, beta)$. The learning objective is to minimize a loss function derived from the maximum likelihood estimation of these parameters. Marginalizing over the unknown mean and variance of the normal distribution, the likelihood of observing the data $y$ given the NIG parameters $m = (gamma, lambda, alpha, beta)$ simplifies to a Student’s t-distribution:
$p(y mid m) = textStleft(textloc=gamma, textscale=fracbeta(1+lambda)lambda alpha,textdf=2alpha right)$
The primary loss component is the negative log-likelihood (NLL) of this t-distribution. Additionally, a regularization term ($Lreg$) is introduced to penalize high evidence associated with high error. This regularization term is defined as $|y – gamma| cdot (2lambda + alpha)$, encouraging the model to reduce its predicted mean ($gamma$) when the error is high, and it’s weighted by a hyperparameter $lambdareg$. The final loss function is a weighted sum:
$L = LNLL + lambdareg L_reg$
The neural network architecture for DER typically involves a standard feed-forward network. The final layer is designed to output four values for each output dimension, corresponding to the parameters of the NIG distribution. Crucially, the softplus activation function is applied to ensure these parameters are positive, with an additional constraint for $alpha > 1$ to ensure that aleatoric uncertainty is well-defined.
Practical Demonstration: Approximating a Cubic Function

To illustrate the practical application of DER, consider the task of approximating a cubic function, $y = x^3$. The training data is generated within a limited window, say $x in [-4, 4]$, and is intentionally corrupted with noise. The goal is to train a DER model to predict the cubic function and accurately quantify uncertainty, especially in regions where training data is scarce.
The training process involves standard deep learning components: a DataLoader for batching, an optimizer (e.g., Adam), and an iterative training loop where the model’s parameters are updated based on the DER loss. After training, the model is used to make predictions on a test set that extends beyond the training interval, for example, $x in [-7, 7]$.
Analyzing the Results
The visualization of the DER model’s output reveals several key insights:
-
Prediction Overlay: The predicted mean of the cubic function closely follows the true function. The uncertainty is visualized as a shaded region around the mean, typically spanning two standard deviations of the total uncertainty (a combination of aleatoric and epistemic).
-
Uncertainty Distribution: As expected, the uncertainty is significantly higher in the regions outside the training interval $[-4, 4]$. This is where the model has limited data and thus exhibits higher epistemic uncertainty. Within the central region where training data is abundant, the uncertainty is lower, reflecting a greater model confidence.

-
Epistemic vs. Aleatoric Ratio: While DER can provide estimates for both types of uncertainty, their disentanglement can sometimes be challenging in practice. Research indicates that DER can sometimes struggle to provide perfectly separated absolute estimates, with high aleatoric uncertainty often correlating with high epistemic uncertainty. A more robust analysis often involves examining the ratio between epistemic and aleatoric uncertainty. In the cubic function example, this ratio is observed to be lower in the central, data-rich region and higher in the extrapolation regions. This indicates that the model attributes more of its uncertainty to a lack of knowledge (epistemic) when predicting far from its training data.
Broader Applications and Future Directions
The principles of Deep Evidential Regression extend beyond simple function approximation. The original DER paper explored its application in depth estimation tasks, and subsequent research has demonstrated its utility in diverse fields such as:
- Video Temporal Grounding: Identifying specific time segments within videos that correspond to given textual descriptions.
- Radiotherapy Dose Prediction: Optimizing radiation therapy plans by predicting the precise dose distribution to target tumors while sparing healthy tissue.
- Image Reconstruction: Improving the quality and reliability of images reconstructed from noisy or incomplete data.
Despite its promising capabilities, DER and EDL are not without their challenges. The optimization landscape can be complex due to the interplay between the negative log-likelihood and the regularization terms. The regularization hyperparameter ($lambda_reg$) can be particularly sensitive, and even small adjustments can significantly impact the quality of the uncertainty estimates. This sensitivity suggests that further research is needed to refine the regularization strategies and improve the robustness of these models.
Key Takeaways for Evidential Deep Learning
Evidential Deep Learning, and DER in particular, represents a significant advancement in the field of uncertainty quantification for machine learning. The core contributions include:

- Higher-Order Distributions: Training models to output parameters for distributions over model parameters, enabling a more nuanced representation of uncertainty.
- Normal Inverse Gamma Modeling: DER’s specific use of the NIG distribution to model the mean and variance of regression targets.
- Computational Efficiency: The ability to quantify both aleatoric and epistemic uncertainty in a single forward pass, offering substantial speedups over traditional methods.
- Compact Representation: A more efficient way to encode uncertainty compared to methods requiring multiple models or complex inference procedures.
However, challenges remain, including:
- Disentanglement Issues: The difficulty in perfectly separating aleatoric and epistemic uncertainty in all scenarios.
- Optimization Complexity: The sensitivity to hyperparameters and the potential for a more challenging optimization landscape.
Nevertheless, Evidential Deep Learning is a rapidly evolving area with immense potential to enhance the trustworthiness and reliability of AI systems across a wide spectrum of applications. As research continues, we can anticipate further refinements and broader adoption of these powerful techniques.
Further Reading and References
For those interested in delving deeper into Evidential Deep Learning and related topics, the following resources are highly recommended:
- Amini, A., Schwarting, W., Zuluaga, M. A., & Sastry, S. S. (2020). Deep evidential regression. arXiv preprint arXiv:2001.01300.
- Sen, B., & Komodakis, N. (2022). Evidential Deep Learning for Out-of-Distribution Detection. arXiv preprint arXiv:2205.10060.
- Bellemare, M. G., Danihelka, I., Gambella, D., Georgiev, P., & Welling, M. (2017). Distributional reinforcement learning with Bayesian neural networks. arXiv preprint arXiv:1707.06447.
- Osband, I., Blundell, C., Pritzel, A., & Van Roy, B. (2016). Deep exploration via bootstrapped DQN. arXiv preprint arXiv:1606.07680.
- Belanger, D., Hudson, L., Simonyan, K., McGann, B., Nardelli, N., Turner, R. E., … & Lakshminarayanan, B. (2019). Eulerian distance-based evidential deep learning for out-of-distribution detection. arXiv preprint arXiv:1905.07311.
- Vergari, A., & Welling, M. (2021). Evidential deep learning for speech recognition. arXiv preprint arXiv:2106.05549.
- Chintala, S., Ver Steeg, G., & Gal, Y. (2020). Deep evidential learning for multi-label classification. arXiv preprint arXiv:2006.06054.





{kind=link}