
The Criticality of Chunking in Enterprise Knowledge Bases: A Deep Dive into Retrieval Failures and Solutions
The initial deployment of an internal knowledge base, a significant milestone for the engineering team, was quickly overshadowed by a critical incident that underscored a fundamental, yet often overlooked, aspect of Retrieval Augmented Generation (RAG) systems: chunking. A seemingly innocuous query from a colleague in the compliance department, seeking information on contractor onboarding processes, yielded a response that was not only confidently delivered but demonstrably incorrect in a way that carried substantial risk. The system provided a general overview of the onboarding process but crucially omitted an exception clause pertinent to contractors engaged in regulated projects. This oversight, stemming from a seemingly technical detail in data processing, highlighted the fragility of RAG systems when their foundational elements are not meticulously engineered.
The root cause of this failure was traced back to the system’s chunking mechanism. While the relevant exception clause was present in the source document and had been successfully ingested and embedded, the retrieval system failed to surface it. The culprit? The document had been segmented into discrete "chunks" in a manner that split the crucial exception clause across two separate segments, rendering each individually incomplete and semantically disconnected. One chunk ended mid-sentence with the standard onboarding process description, while the subsequent chunk began with the qualifying exception, rendering both fragments nonsensical in isolation. This meticulous dissection of information, intended to facilitate retrieval, had inadvertently created an information black hole for critical data.
This incident, which occurred shortly after the internal knowledge base’s first version was shipped, served as a profound realization for the engineering team. The author, reflecting on the moment the compliance query’s flawed response and the granular chunk logs were examined side-by-side, stated, "That moment… is where I stopped treating chunking as a configuration detail and started treating it as the most consequential design decision in the stack." This pivotal experience shifted the team’s perspective from viewing chunking as a mere technical preprocessing step to recognizing it as a core architectural decision with far-reaching implications for system performance and reliability.
Understanding Chunking and Its Underestimation
In the context of RAG pipelines, chunking refers to the process of dividing large documents into smaller, manageable segments or "chunks." These chunks are then vectorized and stored in a knowledge base, from which relevant pieces are retrieved to augment the context provided to a Large Language Model (LLM) for generating responses. As previously highlighted in an introductory article on RAG for enterprise knowledge bases, chunking is often the step where most teams encounter significant difficulties.
The fundamental misunderstanding of chunking’s importance stems from the fact that RAG systems do not retrieve entire documents; they retrieve specific chunks. Every answer generated by the system is derived from these discrete units, not from a holistic understanding of the source material. The precise formulation and content of these chunks dictate the quality of information available to the LLM, thereby influencing the accuracy, coherence, and relevance of its output.
The challenges manifest in several ways:
- Overly Large Chunks: These can contain multiple disparate ideas. The resultant embedding, an average of all contained concepts, may not score highly enough on any single idea to win a retrieval contest, leading to the desired information being overlooked.
- Overly Small Chunks: While precise, these can become "stranded" pieces of information. A single sentence, detached from its surrounding context, may be uninterpretable or insufficient for the LLM to formulate a coherent response.
- Boundary-Splitting Chunks: As evidenced by the compliance incident, information critical to understanding a concept can be split across chunk boundaries, rendering each fragment incomplete and effectively irretrievable in a meaningful way.
A significant reason for the underestimation of chunking is its tendency to fail silently. Unlike a system error that throws an exception, a poorly chunked system produces responses that are often plausible, fluent, and appear almost correct. This subtle inaccuracy, while acceptable in controlled demonstrations with pre-selected queries, erodes user trust in production environments where the full spectrum of real-world queries is encountered. This quiet degradation of trust is often more insidious and harder to rectify than a system that fails with overt errors.
The journey to understanding and optimizing chunking is often a process of iterative discovery, learning from practical failures rather than theoretical blueprints.
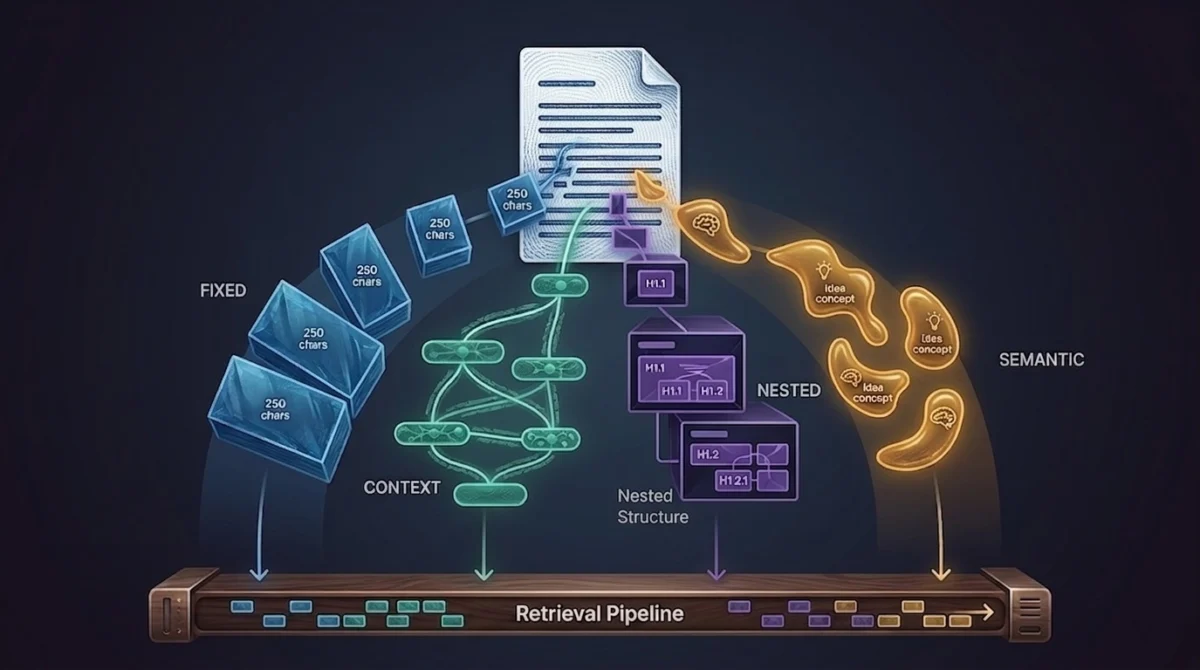
The First Hurdle: Fixed-Size Chunking
The initial approach adopted by many teams, including the one in question, is fixed-size chunking. This method involves splitting documents into segments of a predetermined token count, typically with a defined overlap between consecutive chunks to mitigate boundary issues. For instance, a common configuration might be 512-token chunks with a 50-token overlap. This method is simple to implement and offers predictable index sizes, making it an attractive starting point.
The underlying logic is straightforward: embedding models have token limitations, and documents can be extensive. Fixed-size chunking provides a uniform and manageable segmentation. The overlap aims to ensure that information spanning a chunk boundary has a second opportunity to be captured by a subsequent chunk.
However, this mechanical approach is "completely indifferent to what the text is actually saying." It fails to recognize semantic boundaries, such as the end of a sentence, the entirety of a policy exception, or the distinct steps within a numbered list. Splitting a paragraph mid-argument or a structured list at an arbitrary point produces chunks that are semantically fragmented, even if they meet the token count criteria.
For a corpus comprising Confluence pages, HR policies, and engineering runbooks, this indifference to semantic structure led to tangible issues in context recall. An early RAGAS evaluation revealed a context recall score of 0.72. This metric indicates that approximately one in four queries was missing crucial information present in the corpus. In the context of an internal knowledge base, such a deficit is not negligible; it represents a significant risk of providing incomplete or misleading information, akin to the compliance incident.
While overlap offers some mitigation, it has limitations. A substantial paragraph that happens to cross a chunk boundary cannot be fully compensated for by a mere 50-token overlap. It acts as a patch rather than a fundamental solution. Fixed-size chunking can be effective for highly structured, self-contained documents like FAQs or news summaries, where each entry is largely independent. For more complex and interconnected content, however, its limitations become apparent, necessitating more sophisticated strategies.
Advancing to Smarter Segmentation: Sentence Windows
The contractor onboarding incident, once its cause was understood, clearly articulated a need for a more nuanced approach: the ability to retrieve information at the precision of a single sentence while maintaining the contextual richness of a full paragraph. This dual requirement led to the exploration of sentence-window chunking.

The SentenceWindowNodeParser in LlamaIndex is designed precisely for this purpose. During the indexing phase, it creates one node for each sentence. The sentence itself serves as the retrievable text, while a defined window of surrounding sentences (e.g., three sentences before and three after) is stored in the node’s metadata. At query time, the retriever identifies the most relevant sentence. Subsequently, a post-processor expands this single sentence back to its full contextual window before it is passed to the LLM for generation.
This approach proved highly effective for the problematic contractor exception. The sentence "unless engaged on a project classified under Annex B" was precisely retrievable because it contained the exact information needed for a query about exceptions. The surrounding sentence window then provided the LLM with the necessary context to generate a complete and accurate answer. This transition significantly improved context recall, boosting it from 0.72 to 0.88 on the evaluation set, a substantial improvement that directly addressed the retrieval failures.
However, sentence windows are not a panacea. They falter when encountering structured data like tables or code blocks. A sentence parser has no inherent understanding of table rows or code syntax. It can split a six-column table into dozens of single-sentence nodes, rendering each meaningless in isolation. This creates a new problem when dealing with corpora rich in structured data.
Furthermore, the optimal window_size requires careful tuning. A window of three sentences might suffice for narrative policy text, but for technical runbooks where context might be dispersed across several paragraphs, a larger window might be necessary to capture relevant preceding or succeeding information. Empirical evaluation across different window sizes is crucial to determine the best balance for a specific domain and corpus.
Embracing Structure: Hierarchical Chunking
The engineering corpus presented a different set of challenges. Documents like architecture decision records, system design documents, and API specifications were not characterized by flowing prose but by a distinct hierarchical structure: sections, subsections, numbered steps, tables, and code examples. The sentence-window approach, while effective for narrative text, yielded suboptimal results on these structured documents.
Upon examining the retrieved chunks, it became apparent that queries about API rate limiting, for instance, might surface a sentence from the relevant section, but this sentence might be embedded within a larger chunk detailing a twelve-step configuration process. The crucial numerical data for rate limiting might reside in a table located paragraphs away, outside the retrieved sentence’s immediate context.
The solution lay in recognizing the need to retrieve at a more granular level (e.g., paragraph) while generating with broader context (e.g., section). This led to the implementation of hierarchical chunking. This strategy involves defining a hierarchy of chunk sizes, such as page, section, and paragraph, allowing for retrieval at the most specific relevant level.
The HierarchicalNodeParser in LlamaIndex facilitates this by creating nodes at different levels of granularity. For instance, a document might be parsed into large "page" nodes, which are further subdivided into "section" nodes, and then into smaller "paragraph" nodes. Only the "leaf" nodes (typically the smallest granularity, like paragraphs) are indexed in the vector store for retrieval. However, the full hierarchy is maintained, enabling a mechanism like the AutoMergingRetriever to promote sibling leaf nodes to their parent node during retrieval if they originate from the same section.
This dynamic merging ensures that specific queries can still retrieve precise paragraphs, while broader queries that touch upon multiple aspects of a section can result in the retrieval of the entire section. This approach effectively addresses the issue of context being stripped away by granular chunking, ensuring that tables and other structured elements within a section are accessible.
However, hierarchical chunking is most effective when the source documents possess a genuine structural hierarchy. A quick audit of heading levels within a corpus is advisable. If documents lack meaningful heading structures, the benefits of hierarchical chunking will be limited, and its complexity may not be justified.
The Allure and Pitfalls of Semantic Chunking
Semantic chunking presents an alternative paradigm, aiming to transcend predefined token limits or structural hierarchies. Instead, it leverages embedding models to identify natural topic shifts within a text. When the semantic distance between adjacent sentences crosses a predefined threshold, a chunk boundary is established. In theory, this results in chunks that are semantically coherent and encapsulate a single idea.
The appeal of semantic chunking lies in its potential to create perfectly cohesive chunks, adapting dynamically to the content’s topical flow. However, in production environments, this approach introduces two significant challenges: indexing latency and threshold sensitivity.
The process requires embedding every sentence to determine boundaries, which can be computationally intensive. For large corpora, this can dramatically increase indexing times. A test on a subset of documents revealed that semantic chunking could take up to four times longer than hierarchical chunking. For systems requiring frequent incremental indexing, this latency can become a substantial operational cost.
Threshold sensitivity is another concern. The breakpoint_percentile_threshold dictates how aggressively the parser splits text. A higher threshold leads to fewer, larger chunks, while a lower threshold results in more frequent splitting and smaller chunks. Finding the optimal threshold requires extensive evaluation, as it is dependent on the specific domain, embedding model, and document density. While semantic chunking can excel with unstructured, mixed-format documents where other methods struggle, its trade-off of speed and simplicity for theoretical coherence necessitates strong empirical validation.
Addressing the Unseen: PDFs, Tables, and Slides
The strategies discussed thus far largely assume well-formatted, clean text documents. However, enterprise knowledge bases frequently contain content that defies these assumptions: scanned PDFs with complex layouts, spreadsheets embedded within documents, and slide decks with crucial visual information. These formats often represent the majority of content and pose unique challenges to RAG pipelines.

Scanned PDFs and Layout-Aware Parsing
Standard PDF loaders often struggle with complex layouts, such as multi-column documents or scanned forms. They may interleave text from different columns or garble scanned content. For robust PDF processing, tools like PyMuPDF (fitz) for layout-aware extraction and pdfplumber for granular table detection are essential. PyMuPDF’s get_text('blocks') function provides text grouped by visual blocks, which, when sorted by position, can reconstruct the correct reading order for multi-column layouts. For heavily scanned documents with poor OCR quality, Tesseract OCR can serve as a fallback, though it is slower and less precise. A heuristic approach, such as routing documents to OCR only when PyMuPDF yields minimal text, can optimize performance. LlamaCloud’s LlamaParse offers a managed solution for complex PDF parsing, handling layouts, tables, and diagrams without requiring in-house infrastructure development, though data residency requirements must be considered for regulated environments.
Tables: A Retrieval Black Hole
Tables are a notorious source of silent retrieval failures in RAG systems. Their two-dimensional structure is lost when flattened into a one-dimensional text representation, leading to a loss of row-column relationships. Naively flattening a table can result in a sequence of values that are uninterpretable by embedding models and LLMs, leading to incorrect arithmetic or factual errors in generated responses.
An effective strategy involves treating tables as a separate extraction type. Each row can be reconstructed into a natural language sentence that explicitly encodes the relationship between headers and values. For instance, a row from a sales table could be transformed into "Product: Product A, Region: EMEA, Q3 Revenue: 4.2M, YoY Growth: 12%." This approach ensures that semantically complete chunks are retrievable and interpretable. For highly complex tables, leveraging an LLM to generate prose summaries during indexing can be beneficial, albeit at an increased cost and latency.
Slide Decks and Image-Heavy Documents
PowerPoint presentations and similar slide formats often convey critical information visually, through diagrams and charts, rather than text. Standard text extraction alone is insufficient. Python-pptx can extract slide titles, body text, and speaker notes, with speaker notes often containing dense information. For visual content, multimodal models like GPT-4V or open-source alternatives like LLaVA can generate descriptions of images at indexing time. LlamaParse also offers capabilities for mixed-content extraction, including images. A practical heuristic is to flag slides with minimal text but significant imagery for multimodal processing, optimizing resource allocation.
A Decision Framework for Chunking Strategies
The evolution of chunking strategies leads to the understanding that there is no single "best" approach. Instead, the optimal strategy is contingent on the document type. A pragmatic solution involves implementing a routing logic that selects the most appropriate chunking method based on document characteristics.
This routing can be based on metadata associated with documents during the loading process, such as doc_type (e.g., ‘spec’, ‘policy’, ‘runbook’) or source_format (e.g., ‘pptx’, ‘pdf_complex’). For structured documents with clear hierarchies, hierarchical chunking is suitable. Narrative text benefits from sentence-window parsing. Slide decks and complex PDFs, after initial preprocessing, might be best handled by simpler token-based splitting. A safe default strategy should be in place for unknown or short-form content.
The crucial step is to tag documents with relevant metadata at the loading stage. Retrofitting metadata onto an existing index can be a labor-intensive process. A decision map can guide this selection, prioritizing document structure, content type, and format. This framework treats chunking as a dynamic, context-aware process rather than a one-size-fits-all solution.
The Diagnostic Power of RAGAS
Quantifying the impact of chunking strategies is only possible through rigorous evaluation. Tools like RAGAS are invaluable for this purpose. RAGAS provides core metrics that diagnose different failure modes within a RAG pipeline:
- Context Recall: Measures how much of the ground truth information is present in the retrieved context. Low scores here point to issues in chunking or retrieval.
- Faithfulness: Assesses whether the generated answer is factually consistent with the retrieved context. Low scores indicate generation problems.
- Context Precision: Evaluates the relevance of the retrieved context to the query. Low scores can indicate chunking issues that lead to irrelevant information being surfaced.
The initial context recall score of 0.72, coupled with a reasonable faithfulness score, clearly indicated a retrieval problem stemming from incomplete context. The subsequent improvement to 0.88 after implementing sentence windows, alongside an increase in context precision, validated the effectiveness of this approach for narrative documents.
The key takeaway is to use these metrics diagnostically. A low context recall signals a retrieval or chunking problem, while low faithfulness points to generation issues. Misinterpreting these signals can lead to wasted effort in optimizing the wrong part of the pipeline. Running RAGAS before and after any significant chunking change is essential for data-driven decision-making.
The Enduring Lesson: Chunking as a Foundation
The compliance colleague who flagged the initial error never knew that her query initiated weeks of deep-diving into chunking strategies. From her perspective, the system simply began providing better answers. This disconnect between user experience and engineering complexity is precisely why chunking is so easily underestimated. Users don’t report "poor context recall"; they simply lose trust and gradually stop using the system.
The most impactful habit fostered by this experience is to "evaluate before you optimize." This means running RAGAS on realistic query sets, manually inspecting a random sample of chunks, and examining chunk logs when user issues arise. The evidence for chunking failures is often readily available but frequently overlooked.
Chunking may not be the most glamorous aspect of AI development, but it is the foundational layer upon which the entire RAG pipeline rests. An accurately chunked knowledge base provides the embedding models, retrievers, re-rankers, and LLMs with a fighting chance to perform optimally. Without a solid chunking strategy, even the most advanced models will struggle to deliver reliable and accurate information. Ultimately, the bottleneck in many production RAG systems is not the LLM itself, but the fundamental decision of where one chunk ends and the next begins. This critical decision point dictates the very possibility of effective information retrieval and generation.


Related Posts

Unlocking Engineering Efficiency: A Deep Dive into Anthropic’s Claude Cowork for Enhanced Productivity
Uncertainty Quantification in Machine Learning: A Deep Dive into Evidential Deep Learning and Deep Evidential Regression


{kind=link}